This module provides detail on the design and structure of the SBR Taxonomy, as well as the use of XBRL within it.
It is recommended that you have viewed the XBRL Fundamental modules.
This module covers the following topics:
- Harmonisation and the Reduction of Reporting Burden
- Why XBRL for SBR?
- Overview of SBR's Use of XBRL
- Taxonomy Structure
- Message Implementation Guides
- Taxonomy reference materials
Harmonisation and the Reduction of Reporting Burden
The goal of SBR is to reduce the regulatory reporting burden on business. A key step in this reduction is agreeing common definitions of the information required across all the government agencies involved. This process is called harmonisation.
Harmonisation identifies where there are commonalities across government reports and promotes the use of the same term for the same meaning in multiple places (across both reports and agencies).
There are three main ways that harmonisation can be achieved:
- rationalisation
- standardisation
- normalisation
For the SBR Taxonomy normalisation and standardisation have been an important focus of the development process.
Rationalisation
Rationalisation is the process of identifying elements that are not required to be reported (i.e., are obsolete or redundant). Because rationalisation requires elements to be deleted, it can only be achieved through legislative changes.
As SBR does not change legislation, this option has not been used. For example, SBR will harmonise payroll tax reporting definitions across all state and territories, however this does not change the rate of payroll tax or the date of lodgement.
Standardisation
Standardisation is the process of redefining elements in order to conform to an endorsed standard. This is a top-down approach to harmonisation where conformance is imposed or expected and may involve mapping an element to a defined standard item. The naming of the elements as prescribed by the standard can be adopted.
For example, alignment to AS4590 has resulted in increased consistency of data elements where they have been identified as equivalent. Similarly IFRS-GP has been used where financial data elements have been identified as equivalent. A key aim for the harmonised taxonomy is to use AS4590, IFRS-GP and SBR-core elements wherever possible in preference to local agency variants of such information.
Normalisation
Normalisation is the process of deciding whether elements that seem similar will be treated as equivalent. This includes the definition of the element, as well as its description.
An example of normalisation in SBR is the analysis of the treatment of the label 'Australian Business Number' (ABN). This label appears on a great number of forms in scope for the SBR Taxonomy (approximately 90 times across all forms, sometimes more than once on a form). The names of the labels vary according to the form. Examples include ABN, Australian Business Number, Company ABN, Disclosing Entity ABN etc. However, they are all clearly identifiable as an ABN. As the ABN retains its fundamental nature regardless of the context of the form on which it is placed, these elements were normalised into a single data concept in the SBR Taxonomy.
A second example shows how normalisation occurs for terms that are not identically named, or obviously identical in nature. A label on the Queensland Office of State Revenue Payroll Tax Annual Reconciliation entitled 'Taxable amount' shared the same fundamental properties as the labels from other Revenue offices: 'Amount on which tax is payable' (South Australia), 'Net Taxable Victorian Wages' (Victoria), 'Taxable amount' (New South Wales) and 'Total Taxable Amount' (Tasmania). All of these terms were normalised and represented by a single data concept in the SBR Taxonomy.
Why XBRL for SBR?
SBR has chosen to use eXtensible Business Reporting Language (XBRL) to represent the harmonised definitions of the required items of information, and the description of how those items are assembled for a particular business in a particular reporting obligation.
Using XBRL allows one to map a required reporting item to internal data that a business software package holds. Having established that mapping, anywhere that data item appears on a report, it can be pre-populated from the same source. Users can then submit reports to government from their business' existing financial and accounting systems.
SBR chose XBRL for several reasons:
The reports in scope for the first phase of SBR implementation cover financial and accounting information. XBRL is a standard developed by the financial and accounting community itself specifically for the assembly and reporting of business, financial and accounting data. A key design principle of the Program was to select (wherever possible) existing standards used by the community rather than create a new government based standard.
XBRL supports two key use requirements for SBR – 1) the definition and building of the reporting requirements and 2) the transmission of the data fulfilling those requirements.
- It uses a taxonomy (classification system) to describe and define the data elements and the way they are represented in a reporting obligation,
- The taxonomy is then used to facilitate the electronic exchange of that data between two parties (e.g. business and government).
XBRL allows data items in the business system to be tagged and mapped to the taxonomy, which enables fields in a report to be automatically populated.
XBRL taxonomies allow the association of data items with their clear and unequivocal definitions, improving the ability to compare data across different usages. In other words, the data item or 'fact' represents the same concept each time it appears.
XBRL as a technology is maturing and evolving in capability. One example is validation supported by business rules, which promises to add increased value to SBR-enabled solutions.
Overview of SBR's Use of XBRL
XBRL is flexible and can be implemented in many ways. SBR's use of XBRL reflects design decisions about the use of the technology and the architecture of the taxonomy.
The definitional taxonomy holds the concepts and related descriptions for all of the harmonised data elements from the forms in scope.
The reporting taxonomies draw down relevant concepts from the definitional taxonomy, and add a description of the context and relationship in which those concepts are used in the specific report. This is the mechanics of reuse - the data items are defined once in the definitional taxonomy, and then simply re-used in multiple reports.
A concept is defined once in the definitional taxonomy and is reused in multiple reporting taxonomies (or reports). In the illustration "Address" is defined under Information Classification B, and "Wages and Salaries" under Information Classification A.
A key structural decision was to have a comprehensive definitional taxonomy which is separate from individual report-specific taxonomies. The definitional taxonomy is known as the SBR Taxonomy and the reporting taxonomies are known as SBR Reports.
The definitional taxonomy holds the concepts and related descriptions for all of the harmonised data elements from the forms in scope.
The reporting taxonomies draw down relevant concepts from the definitional taxonomy, and add a description of the context and relationship in which those concepts are used in the specific report. This is the mechanics of reuse - the data items are defined once in the definitional taxonomy, and then simply re-used in multiple reports.
A concept is defined once in the definitional taxonomy and is reused in multiple reporting taxonomies (or reports). For example, "Address" in the model above is defined under Information Classification A, and "Wages and Salaries" under Information Classification B. In this example Address is reused in report X2 and report Y1.Wages and Salaries is reused in report X1 and report Y2. This distinction between where the element is defined (definitional taxonomy) and where it is reused multiple times (reporting taxonomies) is important when working with the SBR taxonomies.
Note: The architecture of the SBR taxonomies influences their versioning. The definitional and reporting taxonomies evolve differently, and their versioning is different as a result.
Also, the SBR taxonomy architecture takes a different approach to the use of dimensions and tuples from other existing examples of XBRL taxonomies (e.g. US-GAAP ). For more information, please see the SBR Taxonomy Architecture Document.
SBR Information Classification System (ICLS)
Separating the definitional taxonomy from reporting taxonomies allows information to be structured differently in the definitional taxonomy than in the reporting taxonomies. The definitional taxonomy uses an information classification system based on the function of the data irrespective of its use within a specific report. The reporting taxonomies subsequently organise information according to the specific business collaborations (or reporting obligations) with agencies.
The SBR ICLS in the definitional taxonomy has eight key subject areas:
- Business Accounting and Financials
- Credit and Insurance
- Education and Training
- Economic Management
- Government Financial Assistance
- Labour Relations
- Party
- Revenue Collection
For descriptions of these subject areas, please see the Taxonomy Architecture page.
Taxonomy Structure
The SBR Taxonomy and Reports are broken up into 6 core components as shown in the following diagram.
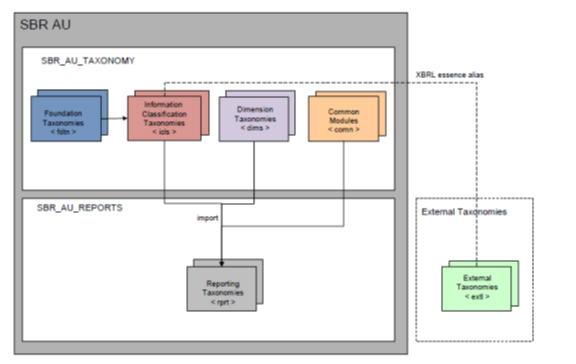
External taxonomies
The SBR program has decided not to be directly bound to external taxonomies unless their quality and change management works in the same predictable and managed way as the Australian SBR Taxonomy. Where the quality and change management is not considered satisfactory from a user/report preparer's perspective. In these cases the Australian SBR Taxonomy will be inspired by them and if necessary, required elements will be included in the SBR Taxonomy, except where there is a direct overlap with the SBR requirements and a wide adoption within the Australian and international communities. This insulates the SBR taxonomy from breaking changes that are out of SBR's control in regards to timeframes and architecture.
The SBR Reports contain a folder for each Government Agency report implemented via the SBR program. Each of these agency report folders contain subfolders that describe the business collaborations (reports) and corresponding messages implemented through the SBR channel.
Message Implementation Guides
A "Message Implementation Guide" (MIG) document supports each SBR report and is the entry point for a software developer who wants to implement a particular business collaboration.
The MIG describes in detail how to use the XBRL taxonomy to create and exchange valid web service messages. It provides business context about the nature of the collaboration and information about the sequence of messages that must flow between the business and government in order to implement it. More specifically, the MIG for each business collaboration contains:
- Message sequence (e.g. list, prefill, lodge)
- Validation rules (schematron
- SOAP Message and header constructs
- XBRL context guidelines
Taxonomy reference materials
Additional information on XBRL and the SBR Taxonomy can be found via the following internet references:
| XBRL Specification (2.1) | http://www.xbrl.org/Specification/XBRL-RECOMMENDATION-2003-12-31+Corrected-Errata-2008-07-02.rtf |
| SBR Taxonomy Architecture Document | Taxonomy architecture information |
| SBR Collaboration Environment | https://www.taxonomy-collaboration.sbr.gov.au/yeti/resources/yeti-gwt/Yeti.jsp |