This module introduces some of the basic concepts of XBRL. The intent is to provide optional background information to support the SBR-specific "Harmonisation, XBRL and the SBR Taxonomy module. It concludes with a list of other existing resources, including some that are more comprehensive or technical in scope.
It is recommended that you have viewed the Introduction to SBR and Delivery of the SBR Program modules.
This module covers the following topics:
- What is XBRL?
- Origins of XBRL
- Understanding XBRL Fundamentals and Terminology
- The Data Modelling Capabilities of XBRL and Taxonomy Extensions
- Who supports XBRL?
- XBRL references
What is XBRL?
XBRL (eXtensible Business Reporting Language) is an open standard mark-up language optimised for business information, including but not limited to financial and accounting information.
It is a variant of XML (eXtensible Markup Language) and adopts the same syntax and related technologies (XML Schema, XLink). XBRL is the optimisation of XML to represent business and financial data.
XML enables the tagging of data with identifying information, according to a classification system (or taxonomy). A taxonomy is essentially a collection of concepts, similar to a dictionary. XBRL tags associate the concepts in the taxonomy to a piece of data, in order to facilitate the interpretation of the data.
XBRL aids data sharing more than XML does by removing the obstacle of human terminology from the equation – any number of human terms for the same data concept can be associated with it (e.g. sales, income, revenue, turnover).
Because XBRL tags are computer-readable, they allow the electronic transmission of data along with resources relating to each concept that help define their semantic meaning (i.e. the associated definitions and other metadata from the taxonomy). Electronic transmission of data with semantic meaning enables the automated processing of that information in context, reducing the time and resources that would otherwise be required to manually analyse and compare it (ref. Understanding XBRL, XBRL Nederland, 2008).
The capability of XBRL to communicate semantic meaning associated with specific data elements, independent of any software application or platform, makes it useful for the transmission of business and financial information to multiple company stakeholders and regulators. It enables the validation of information contained within business transmissions against the constraints defined in the taxonomy and facilitates the analysis and reuse of that business information for other purposes.
Origins of XBRL
XBRL technology arose from the need for more reliable and timely financial and other business related data to be reported to multiple and varied regulatory bodies and company stakeholders. Existing processes and technology created the following issues:
- Duplicated and frequency inconsistent validation methods
- Error-prone and slow manual data collection for analysis
- Introduction of errors as data are transferred along the reporting chain
- Broken audit trails resulting in delays in the reporting cycle
- Wasted effort expended in preparing data in multiple formats for each of the regulators to which a business reports
Accounting professionals sought an open data format that worked for all producers and all consumers of data, capable of sitting between any two systems or standards and interoperating with all of them. The solution needed to be able to transport raw business data along with its business context to ensure all consumers of that information could understand it effectively. It also required the ability to be extended (extensibility) to allow incorporation of future business reporting requirements.
XBRL was developed based on XML, XML Schema and XLink standards to meet these requirements. The diagram below illustrates the progressive development from XML through to XBRL.
| Step | Requirement | Standard |
|---|---|---|
| 1 | Platform and application independent - an open standard to facilitate information sharing across multiple parties | XML |
| 2 | Business data requires context to have meaning | XML |
| 3 | Easily extensible solution to enable future reporting requirements to be captured | XML schema/XLink |
| 4 | Represent relationships between data items in a report. These relationships can be quite complex, vary over time and differ between users | XLink |
| 5 | Set of rules to specify how to fit XML, XML Schema and XLink technologies together to harness the power and flexibility of each | XBRL |
XBRL International
A not-for-profit entity, XBRL International, governs the development and use of XBRL, and has jurisdictions around the world. Other countries are showing interest as adoption increases around the world.
For more information, please visit www.xbrl.org/Jurisdictions
Understanding XBRL Fundamentals and Terminology
Concepts, Schemas, and Taxonomies
A concept is the basic building block of taxonomies (concepts are sometimes referred to as "elements", although element is strictly speaking an XML term). For example, a concept might be "asset" or "income".
A taxonomy contains the definitions of the concepts, the human labels and descriptions associated with them and the interrelationships between concepts. It holds a collection of metadata describing reporting rules and the resources related to concepts / data elements (e.g. types of data, validation and aggregation rules, presentation structures and data dependencies).
SBR has created two types of taxonomy - a definitional taxonomy and reporting taxonomies.
Definition Taxonomies
The definitional taxonomy, known as the SBR Taxonomy, defines the data elements.
A table showing the structure of a Definition Taxonomy
| Information Classification A | Information Classification B | An information classification can have many Subject Area definitions as children |
| Subject Area A 1 | Subject Area B 1 | A Subject Area definition child of the information Classification |
| Subject Area A 2 | Subject Area B 2 | A Subject Area definition child of the information Classification |
| Subject Area A 3 | Subject Area B 3 | A Subhject Area definition child of the information Classification |
Reporting Taxonomies
The reporting taxonomies define the elements used in a particular report along with their presentation structures and business rules.
A table showing the struction of a Definition Taxonomy
| Agency X | Agency Y | An information classification can have many Subject Area definitions as children |
| Form X 1 | Form Y 1 | A Subject Area defintion child of the information Classification |
| Agency X 2 | Agency Y 2 | A Subject Area definition child of the information Classificaiton |
| Agency X | Agency Y | A Subject Area defintion child of the information Classification |
Linkbases
XBRL Taxonomies use linkbases to express relationships between data elements and resources related to them.
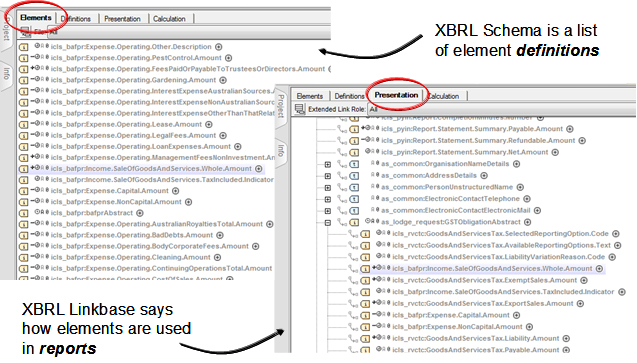
- XBRL Schema is a list of element definitions
- XBRL Linkbase says how elements are used in reports
Linkbases detail the relationships between data elements and hold references to external resources about those elements. Linkbases utilise XML Pointer and XLink technology to localise elements and define the types of relationships between them. There are five types of linkbases defined in the XBRL 2.1 specifications.
| Type of Linkbase | Purpose |
|---|---|
| Presentation Linkbase | Stores information about data interrelationships to effectively organise the taxonomy. Represents hierarchical relationships between data. |
| Calculation Linkbase | Contains definitions of basic validation rules to be applied. |
| Definition Linkbase | Defines different kinds of relations between data elements. There are 4 types of basic relations- general-special, essence-alias, requires-element, similar-tuples. |
| Reference Linkbase | Provides relationships between data elements and external resources such as legislative or regulatory documents. |
| Label Linkbase | Provides alternate labels for elements, e.g. for labels in different languages or for different purposes. |
Facts and dimensions
A fact is a value for a particular data element. In other words, a fact is a particular "instance" of a concept. The appropriate data element is identified in a tag associated with the fact. A fact is always accompanied by a reference to its associated context. Facts and the associated context are held in instance documents.
There are two types of facts used within XBRL - items and tuples.
An item is a single fact which has enough contextual information so that it can be removed from its XBRL instance document and still be understood.
A tuple is the container for a collection of facts and other tuples that cannot stand alone. Tuples group items which do not logically exist outside of that particular grouping. For example, "address line 1" makes no sense outside of a complete "address" made up of multiple facts such as street, state, postcode, etc. All elements in a particular group are required. For example, address line 1, suburb, state AND postcode are all required to make a complete address.
A tuple does not have a context. A tuple describes the grouping, and the facts within that tuple are described with their own contexts.
Here is an example of an XBRL tuple (ref SBR Feb Conference XBRL training - session 4 GLG slide 21):
<ato_tfind:ElectronicContact Telephone>
<icls_pyde:ElectronicContact Telephone ServiceLine Code contextRef="C001">01</icls_pyde:ElectronicContact Telephone ServiceLine Code>
<icls_pyde:ElectronicContact Telephone Area Code contextRef="C001">07</isls_pyde:ElectronicContact Telephone Area Code>
<icls_pyde:ElectronicContact Telephone Minimal Number contextRef="C001">32575000</icls_pyde:ElectronicContact Telephone Minimal Number>
</ato_tfind:ElectronicContact Telephone>
Dimensions (also known as axes) provide additional context to facts. For example, a fact may be characterised by reporting party type or state (e.g. NSW). Dimensions define the allowable set of metadata for a particular context of a fact. For example, the SBR Taxonomy holds the definitions for all the Australian states and territories, but a report specifies a given dimension limiting the set of possible values that dimension may take in that reporting obligation. For example, a NSW payroll report will have a state dimension, where the only valid value will be NSW.
<xbrli:context id="ctx0_USA">
<xbrli:entity>
<xbrli:identifier scheme="http://scheme.xbrl.org">Sample Company</xbrli:identifier>
<xbrli:segment>
<xbrli:explicitMember dimension="tx:Country">tx:USA</xbrli:explicitMember>
</xbrli:segment>
</xbrli:entity>
<xbrli:period>
<xbrli:instant>2007-12-31</xbrli:instant>
</xbrli:period>
<xbrli:context>
Instance Document
An instance document is an instantiation of a taxonomy to a specific report for a given entity and period of time. It is a collection of data that is conformant to the taxonomy and the definitions within it. An instance document contains facts (instances of particular elements) and uses tags defined in one or more taxonomies.
In SBR, an instance document is an electronic version of a set of facts with context, brought together according to the taxonomy to meet a reporting obligation to an agency.
The figure below is an example of an XBRL instance document. At the top is a fact, represented in XBRL, for "income from goods and services". Attached to that fact is a reference to its context (i.e. contextRef="C002").

Note: XBRL differs from XML in the definition of context of facts. In XML, where the same context applies in multiple cases, it will be defined in multiple places. XBRL takes a more normalised approach. Context information is extracted and defined separately from the facts for which it is relevant, allowing a link (or reference) to be made between the two. This promotes re-use and minimises redundant and repeated context definitions.
The instance document above also provides additional information about the "income from goods and services" fact by providing a reference to a unit definition (i.e. unitRef=U1). Here the reference might point to a definition specifying Australian dollars. Any fact reported in Australian dollars will reuse this same unit definition and reference.
At a minimum an XBRL instance document will contain at least one context and at least one fact being reported against that context. Typically there will also be one or more unit definitions.
Context C002 holds basic information, such as entity (xbrli:entity) and associated identifier (xbrli:identifier). In this case the associated identifier is the Australian Business Number or ABN:
<xbrli:identifier scheme="http://www.ato.gov.au/abn">34098932168</xbrli:identifier)
The sample instance document also provides some additional information regarding the time or period relevant to this particular report. Here the report is applicable for the period from 2007-01-01 to 2007-03-31.
Under context, there are two dimensions - reporting party type and the tax obligation type dimension. The latter tells us that the income from sales of goods and services fact is specific to the GST tax obligation:
<xbrldi:explicitMember dimension="h5:TaxObligationTypeDimension">
h5:GST </xbrldi:explicitMember>
If income from sale of goods and services occurred under a different tax obligation, it would be linked to a different context with a different value in that dimension.
Instance Document validation
Instance documents are validated on two levels - on structure and on content.
General validation rules validate structure. They check to ensure an instance document complies with the XML specification (i.e. that it is a 'well-formed' XML message).
Structure is also checked using XBRL validation to ensure:
- Each fact refers to a context
- Each monetary fact refers to a unit of measure
- Dimensions are valid
Business rules, defined in the linkbases within the taxonomy, validate the content of an instance document. Business rules can provide exception handling (such as checking that subtotals add up). Because business rules are defined within the taxonomy, they do not need to be built into individual software applications.
Ref. Understanding XBRL, XBRL Nederland, 2008).
The Data Modelling Capabilities of XBRL and Taxonomy Extensions
XBRL has complex data modelling capabilities. The use of XLink and other components of the XBRL 2.1 specification allow the abstraction of models from raw data. XBRL supports multiple data structures and their simultaneous use. Data structures supported by XBRL include:
- Flat file
- Hierarchy
- Cycles (or recusive definitions)
- Relational data or tuples (the SBR taxonomy uses tuples)
- Dimensional data
All supported structures can be used in a single taxonomy simultaneously, increasing the potential complexity of XBRL solutions. The data model is not static or fixed.
(Ref. Understanding XBRL, XBRL Nederland, 2008).
Extension Taxonomies
An XBRL taxonomy and its data structure can be extended in any direction using extension taxonomies.
Extension taxonomies allow "users to add to a published taxonomy in order to define new elements or change element relationships and attributes" (ref. US SEC, XBRL Glossary).
Extensions are useful in business and financial reporting, where additional concepts not defined in the published taxonomy are required to be reported by an organisation. There are rules and guidelines which govern extension taxonomies, to ensure that the integrity and comparability of data are not lost (ref. IASB XBRL Resources- Fundamentals).
Who supports XBRL?
For a list of XBRL tools, products and service providers, visit www.xbrl.org/tools-and-services.
XBRL references
Additional information on XBRL technology can be found via the following internet references:
| Website | URL |
|---|---|
| XBRL.org International | http://www.xbrl.org |
| XBRL.org Australia | http://www.xbrl.org/au |
| XBRL Business Information Exchange | http://xbrl.squarespace.com/storage/WhatIsXBRL-Summary-2008-05-17.pdf |
| U.S. Securities and Exchange Commission XBRL Glossary - a full glossary of XBRL terms | http://www.sec.gov/spotlight/xbrl/glossary.shtml |
| XBRL Specification (2.0) |
http://www.xbrl.org/Specification/XBRL-RECOMMENDATION-2003-12-31+Corrected-Errata-2008-07-02.rtf |
| International Accounting Standards Board, XBRL Resources - Fundamentals | http://www.iasb.org/XBRL/Resources/Fundamentals.htm |